18 de Julio de 2017 · 17 min de lectura

En un post anterior (Uso del análisis de componentes principales (PCA) para la exploración de datos: paso a paso), hemos introducido la técnica PCA como método de factorización de matrices. En dicha publicación, indicamos que, al trabajar con Machine Learning para el análisis de datos, a menudo nos encontramos con enormes conjuntos de datos que poseen cientos o miles de características o variables diferentes. Como consecuencia, el tamaño del espacio de variables aumenta enormemente, dificultando el análisis de los datos para extraer conclusiones. Para solucionar este problema, la Factorización Matricial es una forma sencilla de reducir la dimensionalidad del espacio de variables cuando se consideran datos multivariantes.
En este blog presentamos otra técnica de reducción de la dimensionalidad para analizar conjuntos de datos multivariantes. En concreto, explicaremos cómo emplear la técnica del Análisis Discriminante Lineal (LDA) para reducir la dimensionalidad del espacio de variables y la compararemos con la técnica PCA, de forma que podamos tener algún criterio sobre cuál debe emplearse en un caso determinado.
El análisis discriminante lineal (LDA) es una generalización del discriminante lineal de (Fisher), un método utilizado en Estadística, reconocimiento de patrones y aprendizaje automático para encontrar una combinación lineal de características que caracterice o separe dos o más clases de objetos o eventos. Este método proyecta un conjunto de datos en un espacio de baja dimensión con buena separabilidad de clases para evitar el exceso de ajuste ("maldición de la dimensionalidad") y reducir los costes computacionales. La combinación resultante puede utilizarse como clasificador lineal o, más comúnmente, para la reducción de la dimensionalidad antes de la clasificación posterior.
El discriminante lineal original se empleó para abordar problemas de clasificación de 2 clases, y más tarde se generalizó como "Análisis Discriminante Lineal multiclase" o "Análisis Discriminante Múltiple" por (C. R. Rao in 1948) (La utilización de medidas múltiples en problemas de clasificación biológica)
En pocas palabras, el objetivo de un LDA suele ser proyectar un espacio de características (un conjunto de datos de muestras $n$-dimensionales) en un subespacio más pequeño $k$ (donde $ k \leq n-1$), manteniendo la información de discriminación de clases. En general, la reducción de la dimensionalidad no sólo ayuda a reducir los costes computacionales para una tarea de clasificación determinada, sino que también puede ser útil para evitar el sobreajuste minimizando el error en la estimación de los parámetros.
Tanto el Análisis Discriminante Lineal (LDA) como el Análisis de Componentes Principales (PCA) son técnicas de transformación lineal que se utilizan habitualmente para la reducción de la dimensionalidad (ambas son técnicas de Factorización Matricial de los datos). La diferencia más importante entre ambas técnicas es que el PCA puede describirse como un algoritmo "no supervisado", ya que "ignora" las etiquetas de clase y su objetivo es encontrar las direcciones (los llamados componentes principales) que maximizan la varianza en un conjunto de datos, mientras que el LDA es un algoritmo "supervisado" que calcula las direcciones ("discriminantes lineales") que representan los ejes que maximizan la separación entre múltiples clases.
Intuitivamente, podríamos pensar que el LDA es superior al PCA para una tarea de clasificación multiclase en la que se conocen las etiquetas de las clases. Sin embargo, esto no siempre es así. Por ejemplo, las comparaciones entre las precisiones de clasificación para el reconocimiento de imágenes después de utilizar PCA o LDA, muestran que PCA tiende a superar a LDA si el número de muestras por clase es relativamente pequeño (PCA vs. LDA, A.M. Martínez et al., 2001). En la práctica, no es infrecuente utilizar tanto LDA como PCA en combinación: por ejemplo, PCA para la reducción de la dimensionalidad seguido de LDA.
En pocas palabras, podemos decir que el PCA es un algoritmo no supervisado que intenta encontrar los ejes de componentes ortogonales de máxima varianza en un conjunto de datos (véase nuestro post anterior sobre este tema), mientras que el objetivo del LDA como algoritmo supervisado es encontrar el subespacio de características que optimiza la separabilidad de las clases. En la siguiente figura, podemos ver un esquema conceptual que nos ayuda a tener una noción geométrica sobre ambos métodos
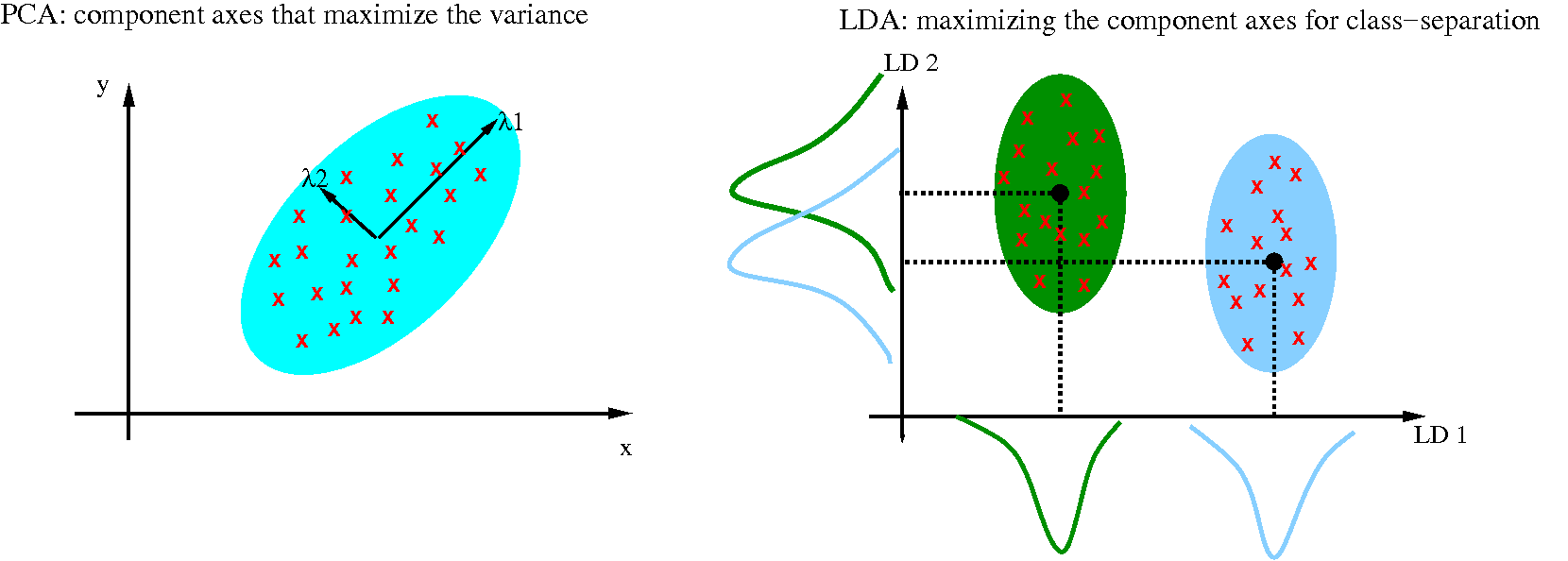
Como se muestra en el eje x (nuevo componente LD 1 en la dimensionalidad reducida) y en el eje y (nuevo componente LD 2 en la dimensionalidad reducida) en la parte derecha de la figura anterior, el LDA separar bien las dos clases de distribución normal.
La siguiente pregunta es: ¿Cuál es un "buen" subespacio de características que maximiza los ejes de componentes para la separación de clases?.
Para responder a esta pregunta, supongamos que nuestro objetivo es reducir las dimensiones de un conjunto de datos d -dimensional proyectándolo en un subespacio (k)-dimensional (donde k<d). Entonces, ¿cómo sabemos qué tamaño debemos elegir para k (k = el número de dimensiones del nuevo subespacio de características), y cómo sabemos si tenemos un espacio de características que representa "bien" nuestros datos?
Para ello, calcularemos los vectores propios (los componentes) de nuestro conjunto de datos y los recogeremos en las denominadas matrices de dispersión (es decir, la matriz de dispersión entre clases y la matriz de dispersión dentro de la clase). Cada uno de estos vectores propios se asocia a un valor propio, que nos indica la "longitud" o "magnitud" de los vectores propios.
Si observamos que todos los valores propios tienen una magnitud similar, esto puede ser un buen indicador de que nuestros datos ya están proyectados en un "buen" espacio de características.
Y en el otro escenario, si algunos de los valores propios son mucho más grandes que otros, podríamos estar interesados en mantener sólo aquellos vectores propios con los valores propios más altos, ya que contienen más información sobre la distribución de nuestros datos. En el otro caso, si los valores propios que están cerca de 0 son menos informativos, podríamos considerar la posibilidad de descartarlos para construir el nuevo subespacio de características (el mismo procedimiento que en el caso del PCA).
Pasemos a enumeramos los 5 pasos generales para realizar un análisis discriminante lineal que exploraremos con más detalle en las siguientes secciones.
Calcular los vectores medios $dimensionales$ para las diferentes clases del conjunto de datos.
Calcular las matrices de dispersión (matriz de dispersión entre clases y dentro de clases).
Calcular los vectores propios ($e_1,e_2,...,e_d$) y los valores propios correspondientes ($\lambda_1,\lambda_2,...\lambda_d$) para las matrices de dispersión.
Ordenar los eigenvectores por valores propios decrecientes y elegir k eigenvectores con los mayores valores propios para formar una matriz $d \times k$ dimensional $W$ (donde cada columna representa un eigenvector).
Utilice esta matriz de vectores propios $d \times k$ para transformar las muestras en el nuevo subespacio. Esto se puede resumir con la multiplicación de matrices: $Y=X \times W$, donde $X$ es una matriz $n \times d-dimensional$ que representa las $n$ muestras, y $y$ son las muestras transformadas $n \times k-dimensional$ en el nuevo subespacio.
Para fijar los conceptos, aplicamos estos 5 pasos en el conjunto de datos del iris para la clasificación de flores.
Para el siguiente tutorial, trabajaremos con el famoso conjunto de datos "Iris" que podemos encontrar en UCI machine learning repository (https://archive.ics.uci.edu/ml/datasets/Iris).
El conjunto de datos de iris contiene mediciones de 150 flores de iris de tres especies diferentes.
Las tres clases del conjunto de datos de Iris:
Las cuatro características del conjunto de datos de Iris:
feature_dict = {i:label for i,label in zip(
range(4),
('sepal length in cm',
'sepal width in cm',
'petal length in cm',
'petal width in cm', ))}
Cargamos los datos y generamos el data frame:
import pandas as pd
df = pd.io.parsers.read_csv(
filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None,
sep=',',
)
df.columns = [l for i,l in sorted(feature_dict.items())] + ['class label']
df.dropna(how="all", inplace=True) # to drop the empty line at file-end
df.tail()
En forma de matriz y en notación matemática
$
\mathbf{X} = \begin{bmatrix} x_{1_{\text{sepal length}}} & x_{1_{\text{sepal width}}} & x_{1_{\text{petal length}}} & x_{1_{\text{petal width}}} \newline
... \newline
x_{2_{\text{sepal length}}} & x_{2_{\text{sepal width}}} & x_{2_{\text{petal length}}} & x_{2_{\text{petal width}}} \newline
\end{bmatrix}, y = \begin{bmatrix} \omega_{\text{iris-setosa}}\newline
... \newline
\omega_{\text{iris-virginica}}\newline \end{bmatrix}$
Como es más conveniente trabajar con valores numéricos, utilizaremos el LabelEncode de la biblioteca scikit-learn para convertir las etiquetas de las clases en números: 1, 2 y 3.
%matplotlib inline
from sklearn.preprocessing import LabelEncoder
X = df[[0,1,2,3]].values
y = df['class label'].values
enc = LabelEncoder()
label_encoder = enc.fit(y)
y = label_encoder.transform(y) + 1
label_dict = {1: 'Setosa', 2: 'Versicolor', 3:'Virginica'}
Obtenemos
$y = \begin{bmatrix}{\text{setosa}}\newline {\text{setosa}}\newline ... \newline {\text{virginica}}\end{bmatrix} \quad \Rightarrow \begin{bmatrix} {\text{1}}\ {\text{1}} \newline ... \newline {\text{3}}\end{bmatrix}$
Para tener una idea aproximada de cómo se distribuyen las muestras de nuestras tres clases $\omega_1, \omega_2$ y $\omega_3$, vamos a visualizar las distribuciones de las cuatro características diferentes en histogramas unidimensionales.
%matplotlib inline
from matplotlib import pyplot as plt
import numpy as np
import math
fig, axes = plt.subplots(nrows=2, ncols=2, figsize=(12,6))
for ax,cnt in zip(axes.ravel(), range(4)):
# set bin sizes
min_b = math.floor(np.min(X[:,cnt]))
max_b = math.ceil(np.max(X[:,cnt]))
bins = np.linspace(min_b, max_b, 25)
# plottling the histograms
for lab,col in zip(range(1,4), ('blue', 'red', 'green')):
ax.hist(X[y==lab, cnt],
color=col,
label='class %s' %label_dict[lab],
bins=bins,
alpha=0.5,)
ylims = ax.get_ylim()
# plot annotation
leg = ax.legend(loc='upper right', fancybox=True, fontsize=8)
leg.get_frame().set_alpha(0.5)
ax.set_ylim([0, max(ylims)+2])
ax.set_xlabel(feature_dict[cnt])
ax.set_title('Iris histogram #%s' %str(cnt+1))
# hide axis ticks
ax.tick_params(axis="both", which="both", bottom="off", top="off",
labelbottom="on", left="off", right="off", labelleft="on")
# remove axis spines
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
axes[0][0].set_ylabel('count')
axes[1][0].set_ylabel('count')
fig.tight_layout()
plt.show()
Con sólo mirar estas simples representaciones gráficas de las características, ya podemos decir que las longitudes y anchuras de los pétalos son probablemente más adecuadas como características potenciales para separar entre las tres clases de flores. En la práctica, en lugar de reducir la dimensionalidad mediante una proyección (aquí: LDA), una buena alternativa sería una técnica de selección de características. Para conjuntos de datos de baja dimensión como Iris, un vistazo a esos histogramas ya sería muy informativo. Otra técnica sencilla, pero muy útil, sería utilizar algoritmos de selección de características (see rasbt.github.io/mlxtend/user_guide/feature_selection/SequentialFeatureSelector y scikit-learn).
Nota importante sobre los supuestos de normalidad : Hay que mencionar que el LDA asume datos con distribución normal, características que son estadísticamente independientes y matrices de covarianza idénticas para cada clase. Sin embargo, esto sólo se aplica a LDA como clasificador y LDA para la reducción de la dimensionalidad también puede funcionar razonablemente bien si se violan esos supuestos. E incluso para tareas de clasificación, LDA parece ser bastante robusto a la distribución de los datos.
Después de pasar por varios pasos de preparación, nuestros datos están finalmente listos para el LDA real. En la práctica, el LDA para la reducción de la dimensionalidad sería simplemente otro paso de preprocesamiento para una tarea típica de aprendizaje automático o de clasificación de patrones.
En este primer paso, empezaremos con un simple cálculo de los vectores medios $m_i$, $(i=1,2,3)$ de las 3 clases de flores diferentes:
$ m_i = \begin{bmatrix} \mu_{\omega_i (\text{sepal length)}}\newline \mu_{\omega_i (\text{sepal width})}\newline \mu_{\omega_i (\text{petal length)}}\newline \mu_{\omega_i (\text{petal width})}\newline \end{bmatrix} \; , \quad \text{with} \quad i = 1,2,3$
np.set_printoptions(precision=4)
mean_vectors = []
for cl in range(1,4):
mean_vectors.append(np.mean(X[y==cl], axis=0))
print('Mean Vector class %s: %s\n' %(cl, mean_vectors[cl-1]))
Se obtiene:
Mean Vector class 1: [ 5.006 3.418 1.464 0.244]
Mean Vector class 2: [ 5.936 2.77 4.26 1.326]
Mean Vector class 3: [ 6.588 2.974 5.552 2.026]
Ahora, calcularemos las dos matrices de 4x4 dimensiones: La matriz de dispersión dentro de la clase y la matriz de dispersión entre clases.
La matriz de dispersión dentro de la clase SW se calcula mediante la siguiente ecuación:
$ S_W = \sum\limits_{i=1}^{c} S_i$
dónde
$ S_i = \sum\limits_{\pmb x \in D_i}^n (\pmb x - \pmb m_i)\;(\pmb x - \pmb m_i)^T $
y $m_i$ es el vector medio
$ \pmb m_i = \frac{1}{n_i} \sum\limits_{\pmb x \in D_i}^n \; \pmb x_k$
S_W = np.zeros((4,4))
for cl,mv in zip(range(1,4), mean_vectors):
class_sc_mat = np.zeros((4,4)) # scatter matrix for every class
for row in X[y == cl]:
row, mv = row.reshape(4,1), mv.reshape(4,1) # make column vectors
class_sc_mat += (row-mv).dot((row-mv).T)
S_W += class_sc_mat # sum class scatter matrices
print('within-class Scatter Matrix:\n', S_W)
Obtnemos:
within-class Scatter Matrix:
[[ 38.9562 13.683 24.614 5.6556]
[ 13.683 17.035 8.12 4.9132]
[ 24.614 8.12 27.22 6.2536]
[ 5.6556 4.9132 6.2536 6.1756]]
Como alternativa, también podríamos calcular las matrices de covarianza de clase añadiendo el factor de escala $\frac{1}{N-1}$ a la matriz de dispersión por lo que nuestra ecuación se convierte en
$S_i = \frac{1}{N_{i}-1} \sum\limits_{\pmb x \in D_i}^n (\pmb x - \pmb m_i)\;(\pmb x - \pmb m_i)^T$
y
$S_W = \sum\limits_{i=1}^{c} (N_{i}-1) S_i$
donde $N_i$ es el tamaño de la muestra de la clase respectiva (aquí: 50), y en este caso particular, podemos eliminar el término ($N_i-1$) ya que todas las clases tienen el mismo tamaño de muestra.
Sin embargo, los espacios propios resultantes serán idénticos (vectores propios idénticos, sólo los valores propios se escalan de forma diferente por un factor constante).
2.2 Matriz de dispersión entre clases $S_B$
La matriz de dispersión entre clases $S_B$ se calcula mediante la siguiente ecuación
$S_B = \sum\limits_{i=1}^{c} N_{i} (\pmb m_i - \pmb m) (\pmb m_i - \pmb m)^T$
donde $m$ es la media global, y $m_i$ y $N_i$ son la media y el tamaño de las muestras de las respectivas clases.
overall_mean = np.mean(X, axis=0)
S_B = np.zeros((4,4))
for i,mean_vec in enumerate(mean_vectors):
n = X[y==i+1,:].shape[0]
mean_vec = mean_vec.reshape(4,1) # make column vector
overall_mean = overall_mean.reshape(4,1) # make column vector
S_B += n * (mean_vec - overall_mean).dot((mean_vec - overall_mean).T)
print('between-class Scatter Matrix:\n', S_B)
Obtenemos
between-class Scatter Matrix:
[[ 63.2121 -19.534 165.1647 71.3631]
[ -19.534 10.9776 -56.0552 -22.4924]
[ 165.1647 -56.0552 436.6437 186.9081]
[ 71.3631 -22.4924 186.9081 80.6041]]
A continuación, resolveremos el problema de valores propios generalizado para la matriz $S_{W}^{-1} S_{B}$ para obtener los discriminantes lineales.
eig_vals, eig_vecs = np.linalg.eig(np.linalg.inv(S_W).dot(S_B))
for i in range(len(eig_vals)):
eigvec_sc = eig_vecs[:,i].reshape(4,1)
print('\nEigenvector {}: \n{}'.format(i+1, eigvec_sc.real))
print('Eigenvalue {:}: {:.2e}'.format(i+1, eig_vals[i].real))
Obteniendo
Eigenvector 1:
[[-0.2049]
[-0.3871]
[ 0.5465]
[ 0.7138]]
Eigenvalue 1: 3.23e+01
Eigenvector 2:
[[-0.009 ]
[-0.589 ]
[ 0.2543]
[-0.767 ]]
Eigenvalue 2: 2.78e-01
Eigenvector 3:
[[ 0.179 ]
[-0.3178]
[-0.3658]
[ 0.6011]]
Eigenvalue 3: -4.02e-17
Eigenvector 4:
[[ 0.179 ]
[-0.3178]
[-0.3658]
[ 0.6011]]
Eigenvalue 4: -4.02e-17
Tras esta descomposición de nuestra matriz cuadrada en vectores propios y valores propios, recapitulemos brevemente cómo podemos interpretar esos resultados. Tanto los vectores propios como los valores propios nos proporcionan información sobre la distorsión de una transformación lineal: Los vectores propios son básicamente la dirección de esta distorsión, y los valores propios son el factor de escala para los vectores propios que describen la magnitud de la distorsión.
Si realizamos el LDA para reducir la dimensionalidad, los vectores propios son importantes, ya que formarán los nuevos ejes de nuestro nuevo subespacio de características; los valores propios asociados son de especial interés, ya que nos dirán lo "informativos" que son los nuevos "ejes".
Comprobemos brevemente nuestro cálculo y hablemos más de los valores propios a continuación.
$\pmb A\pmb{v} = \lambda\pmb{v}$
dónde, $ \pmb A = S_{W}^{-1}S_B$, $ \pmb {v} = \text{Eigenvector}$ and $\lambda = \text{Eigenvalue}$
for i in range(len(eig_vals)):
eigv = eig_vecs[:,i].reshape(4,1)
np.testing.assert_array_almost_equal(np.linalg.inv(S_W).dot(S_B).dot(eigv),
eig_vals[i] * eigv,
decimal=6, err_msg='', verbose=True)
print('ok')
obtenemos un
ok
Recuerde de la introducción que no sólo estamos interesados en proyectar los datos en un subespacio que mejore la separabilidad de la clase, sino que también reduce la dimensionalidad de nuestro espacio de características, (donde los vectores propios formarán los ejes de este nuevo subespacio de características).
Sin embargo, los vectores propios sólo definen las direcciones del nuevo eje, ya que todos tienen la misma longitud unitaria 1.
Por lo tanto, para decidir qué vector propio queremos dejar para nuestro subespacio de dimensiones inferiores, tenemos que echar un vistazo a los correspondientes valores propios de los vectores propios. A grandes rasgos, los vectores propios con los valores propios más bajos son los que menos información aportan sobre la distribución de los datos, y esos son los que queremos descartar. El enfoque común es clasificar los vectores propios de mayor a menor valor propio correspondiente y elegir los primeros $k$ vectores propios.
Vamos a ello:
# Make a list of (eigenvalue, eigenvector) tuples
eig_pairs = [(np.abs(eig_vals[i]), eig_vecs[:,i]) for i in range(len(eig_vals))]
# Sort the (eigenvalue, eigenvector) tuples from high to low
eig_pairs = sorted(eig_pairs, key=lambda k: k[0], reverse=True)
# Visually confirm that the list is correctly sorted by decreasing eigenvalues
print('Eigenvalues in decreasing order:\n')
for i in eig_pairs:
print(i[0])
obtenemos
Eigenvalues in decreasing order:
32.2719577997
0.27756686384
5.71450476746e-15
5.71450476746e-15
Si echamos un vistazo a los valores propios, ya podemos ver que 2 valores propios están cerca de 0. La razón por la que están cerca de 0 no es que no sean informativos, sino que se debe a la imprecisión del punto flotante. De hecho, estos dos últimos valores propios deberían ser exactamente cero: En LDA, el número de discriminantes lineales es como máximo $c-1$ donde $c$ es el número de etiquetas de clase, ya que la matriz de dispersión intermedia $S_B$ es la suma de $c$ matrices con rango 1 o menos. Tenga en cuenta que en el raro caso de colinealidad perfecta (todos los puntos de muestra alineados caen en una línea recta), la matriz de covarianza tendría rango uno, lo que daría lugar a un solo vector propio con un valor propio distinto de cero.
Ahora, expresemos la "varianza explicada" como porcentaje:
print('Variance explained:\n')
eigv_sum = sum(eig_vals)
for i,j in enumerate(eig_pairs):
print('eigenvalue {0:}: {1:.2%}'.format(i+1, (j[0]/eigv_sum).real))
se obtiene
Variance explained:
eigenvalue 1: 99.15%
eigenvalue 2: 0.85%
eigenvalue 3: 0.00%
eigenvalue 4: 0.00%
El primer par propio es, con mucho, el más informativo, y no perderemos mucha información si formamos un espaciado de características 1D basado en este par propio.
4.2. Elección de los k vectores propios con los mayores valores propios
Después de ordenar los pares propios por valores propios decrecientes, es el momento de construir nuestra matriz de vectores propios $k \times d-dimensional$ (aquí 4×2: basado en los 2 pares propios más informativos) y por lo tanto reducir el espacio inicial de características de 4 dimensiones en un subespacio de características de 2 dimensiones.
W = np.hstack((eig_pairs[0][1].reshape(4,1), eig_pairs[1][1].reshape(4,1)))
print('Matrix W:\n', W.real)
se obtiene
Matrix W:
[[ 0.2049 -0.009 ]
[ 0.3871 -0.589 ]
[-0.5465 0.2543]
[-0.7138 -0.767 ]]
En el último paso, utilizamos la matriz $4 \times 2-dimensional$ dimensional $W$ que acabamos de calcular para transformar nuestras muestras en el nuevo subespacio mediante la ecuación $Y=X \times W$.
donde $X$ es una matriz $ n \times d-dimensional$ que representa las muestras $n$, y $Y$ son las muestras transformadas $n \times k-dimensional$ en el nuevo subespacio.
X_lda = X.dot(W)
assert X_lda.shape == (150,2), "The matrix is not 150x2 dimensional."
graficamos los resultados
from matplotlib import pyplot as plt
def plot_step_lda():
ax = plt.subplot(111)
for label,marker,color in zip(
range(1,4),('^', 's', 'o'),('blue', 'red', 'green')):
plt.scatter(x=X_lda[:,0].real[y == label],
y=X_lda[:,1].real[y == label],
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label]
)
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title('LDA: Iris projection onto the first 2 linear discriminants')
# hide axis ticks
plt.tick_params(axis="both", which="both", bottom="off", top="off",
labelbottom="on", left="off", right="off", labelleft="on")
# remove axis spines
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
plt.grid()
plt.tight_layout
plt.show()
plot_step_lda()
El gráfico de dispersión anterior representa nuestro nuevo subespacio de características que hemos construido mediante LDA. Podemos ver que el primer discriminante lineal "LD1" separa bastante bien las clases. Sin embargo, el segundo discriminante, "LD2", no añade mucha información valiosa, lo que ya hemos concluido cuando miramos los valores propios clasificados en el paso 4.
Ahora, después de haber visto cómo funciona un Análisis Discriminante Lineal utilizando un enfoque paso a paso, también hay una manera más conveniente de lograr lo mismo a través de la clase LDA implementada en la biblioteca de aprendizaje de máquinas scikit-learn.
# import library
import pandas as pd
from sklearn.preprocessing import LabelEncoder
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from matplotlib import pyplot as plt
feature_dict = {i:label for i,label in zip(
range(4),
('sepal length in cm',
'sepal width in cm',
'petal length in cm',
'petal width in cm', ))}
# Reading in the dataset
df = pd.io.parsers.read_csv(
filepath_or_buffer='https://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',
header=None,
sep=',',
)
df.columns = [l for i,l in sorted(feature_dict.items())] + ['class label']
df.dropna(how="all", inplace=True) # to drop the empty line at file-end
# use the LabelEncode from the scikit-learn library to convert the class labels into numbers: 1, 2, and 3
X = df[[0,1,2,3]].values
y = df['class label'].values
enc = LabelEncoder()
label_encoder = enc.fit(y)
y = label_encoder.transform(y) + 1
label_dict = {1: 'Setosa', 2: 'Versicolor', 3:'Virginica'}
# LDA
sklearn_lda = LDA(n_components=2)
X_lda_sklearn = sklearn_lda.fit_transform(X, y)
def plot_scikit_lda(X, title):
ax = plt.subplot(111)
for label,marker,color in zip(
range(1,4),('^', 's', 'o'),('blue', 'red', 'green')):
plt.scatter(x=X[:,0][y == label],
y=X[:,1][y == label] * -1, # flip the figure
marker=marker,
color=color,
alpha=0.5,
label=label_dict[label])
plt.xlabel('LD1')
plt.ylabel('LD2')
leg = plt.legend(loc='upper right', fancybox=True)
leg.get_frame().set_alpha(0.5)
plt.title(title)
# hide axis ticks
plt.tick_params(axis="both", which="both", bottom="off", top="off",
labelbottom="on", left="off", right="off", labelleft="on")
# remove axis spines
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_visible(False)
ax.spines["left"].set_visible(False)
plt.grid()
plt.tight_layout
plt.show()
plot_scikit_lda(X_lda_sklearn, title='Default LDA via scikit-learn')
y el resultado es
En esta artículo hemos continuado con la introducción a las técnicas de Factorización Matricial para la reducción de la dimensionalidad en conjuntos de datos multivariantes. En concreto en este post, hemos descrito los pasos básicos y los conceptos principales para analizar datos mediante el uso del Análisis Discriminante Lineal (LDA). Hemos mostrado la versatilidad de esta técnica a través de un ejemplo, y hemos descrito cómo se pueden interpretar los resultados de la aplicación de esta técnica.










