24 de Enero de 2018 · 18 min de lectura

Este tutorial muestra cómo guardar y restaurar las variables de una red neuronal cread en TensorFlow. Durante la optimización guardamos las variables de la red neuronal siempre que su precisión de clasificación haya mejorado en el conjunto de validación. La optimización se cancela cuando no ha habido mejoras para 1000 iteraciones. Luego, volvemos a cargar las variables que obtuvieron mejores resultados en el conjunto de validación.
Esta estrategia se llama Early Stopping. Se usa para evitar el sobreajuste (Overfitting) de la red neuronal. Esto ocurre cuando la red neuronal se está entrenando durante demasiado tiempo, por lo que comienza a aprender el ruido del conjunto de entrenamiento, lo que podría causar que la red neuronal clasifique incorrectamente las imágenes nuevas.
El sobreajuste no es realmente un problema para la red neuronal utilizada en este tutorial en el conjunto de datos MNIST para el reconocimiento de dígitos escritos a mano. Pero este tutorial muestra la idea general en el uso del Early Stopping cómo técnica.
Seguiremos utilizando el ejemplo usado en los tutoriales anetrioeres (ver tutoriales I,II,III,IV) para mostrar como guardar y recuperar las variables de la red neuronal. Partamos del mismo esquema de la red neuronal convolucinal que queremos implementar para la tarea del reconocimiento de dígitos escritos a mano, con el fin dera terner presente la estructura de nuestra red, tal y como hemos encho en los tutoriales anteriores.

Importamos las librerías. Utilizaremos la libreria PrettyTensor para simplificar la construcción de redes neuronales (ver tutorial III para más detalles).
%matplotlib inline
import matplotlib.pyplot as plt
import tensorflow as tf
import numpy as np
from sklearn.metrics import confusion_matrix
import time
from datetime import timedelta
import math
import os
# Use PrettyTensor to simplify Neural Network construction.
import prettytensor as pt
Cargamos los datos
from tensorflow.examples.tutorials.mnist import input_data
data = input_data.read_data_sets('data/MNIST/', one_hot=True)
Extracting data/MNIST/train-images-idx3-ubyte.gz
Extracting data/MNIST/train-labels-idx1-ubyte.gz
Extracting data/MNIST/t10k-images-idx3-ubyte.gz
Extracting data/MNIST/t10k-labels-idx1-ubyte.gz
Las etiquetas de clase son codificadas por One-Hot, lo que significa que cada etiqueta es un vector con 10 elementos, todos los cuales son cero a excepción de un elemento. El índice de este elemento es el número de clase, es decir, el dígito que se muestra en la imagen asociada. También necesitamos los números de clase como enteros para el conjunto de pruebas, por lo que ahora lo calculamos.
data.test.cls = np.argmax(data.test.labels, axis=1)
data.validation.cls = np.argmax(data.validation.labels, axis=1)
Pasamos a definir el conjunto de variables para dar formato a las dimensiones de nuestras imágenes:
# We know that MNIST images are 28 pixels in each dimension.
img_size = 28
# Images are stored in one-dimensional arrays of this length.
img_size_flat = img_size * img_size
# Tuple with height and width of images used to reshape arrays.
img_shape = (img_size, img_size)
# Number of colour channels for the images: 1 channel for gray-scale.
num_channels = 1
# Number of classes, one class for each of 10 digits.
num_classes = 10
Crearemos nuestra función que es utilizada para trazar las 9 imágenes en una cuadrícula de 3x3 y escribir las clases verdaderas y predichas debajo de cada imagen.
def plot_images(images, cls_true, cls_pred=None):
assert len(images) == len(cls_true) == 9
# Create figure with 3x3 sub-plots.
fig, axes = plt.subplots(3, 3)
fig.subplots_adjust(hspace=0.3, wspace=0.3)
for i, ax in enumerate(axes.flat):
# Plot image.
ax.imshow(images[i].reshape(img_shape), cmap='binary')
# Show true and predicted classes.
if cls_pred is None:
xlabel = "True: {0}".format(cls_true[i])
else:
xlabel = "True: {0}, Pred: {1}".format(cls_true[i], cls_pred[i])
# Show the classes as the label on the x-axis.
ax.set_xlabel(xlabel)
# Remove ticks from the plot.
ax.set_xticks([])
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
Miramos algunos datos
# Get the first images from the test-set.
images = data.test.images[0:9]
# Get the true classes for those images.
cls_true = data.test.cls[0:9]
# Plot the images and labels using our helper-function above.
plot_images(images=images, cls_true=cls_true)

Creamos las variables de marcador de posición (Placeholder variables) como hicimos en los tutoriales anteriores:
x = tf.placeholder(tf.float32, shape=[None, img_size_flat], name='x')
x_image = tf.reshape(x, [-1, img_size, img_size, num_channels])
y_true = tf.placeholder(tf.float32, shape=[None, 10], name='y_true')
#y_true_cls = tf.argmax(y_true, dimension=1)
y_true_cls = tf.argmax(y_true, axis=1)
Creamos la estructura de la red neuronal
Esta sección implementa la Red Neural Convolucional usando Pretty Tensor (veáse Tutorial III).
x_pretty = pt.wrap(x_image)
with pt.defaults_scope(activation_fn=tf.nn.relu):
y_pred, loss = x_pretty.\
conv2d(kernel=5, depth=16, name='layer_conv1').\
max_pool(kernel=2, stride=2).\
conv2d(kernel=5, depth=36, name='layer_conv2').\
max_pool(kernel=2, stride=2).\
flatten().\
fully_connected(size=128, name='layer_fc1').\
softmax_classifier(num_classes=num_classes, labels=y_true)
Creamos nuestra función para obtener los pesos de los filtros
def get_weights_variable(layer_name):
# Retrieve an existing variable named 'weights' in the scope
# with the given layer_name.
# This is awkward because the TensorFlow function was
# really intended for another purpose.
with tf.variable_scope(layer_name, reuse=True):
variable = tf.get_variable('weights')
return variable
weights_conv1 = get_weights_variable(layer_name='layer_conv1')
weights_conv2 = get_weights_variable(layer_name='layer_conv2')
método de optimización en la función de coste:
# Optimization Method
optimizer = tf.train.AdamOptimizer(learning_rate=1e-4).minimize(loss)
Medida de desempeño
y_pred_cls = tf.argmax(y_pred, axis=1)
Luego creamos un vector de booleanos que nos dice si la clase predicha es igual a la clase verdadera de cada imagen.
correct_prediction = tf.equal(y_pred_cls, y_true_cls)
Calculamos la precisión (accuracy) de la clasificación y transforma los booleanos a floats, de modo que False se convierte en 0 y True se convierte en 1. Luego calculamos el promedio de estos números.
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
Hasta ahora solo hemos creado nuestro grafo para la tarea requerida. Ahora queremos guardar el valor de las variables de la red neuronal. Para ello creamos un objeto que llamaremos saver, y que se utiliza para almacenar y recuperar todas las variables del gráfico TensorFlow. Nada se guarda realmente en este punto, esto lo haremos más adelante en la función optimize().
saver = tf.train.Saver()
Los archivos guardados a menudo se llaman puntos de control porque pueden escribirse a intervalos regulares durante la optimización. Este es el directorio utilizado para guardar y recuperar los datos.
save_dir = 'checkpoints/'
Crea el directorio si no existe.
if not os.path.exists(save_dir):
os.makedirs(save_dir)
Esta es la ruta para el archivo punto de control. Y salvamos los parámetros de y valor de las variables del grafo cuyo test devuelva el mejor desempeño.
save_path = os.path.join(save_dir, 'best_validation')
Una vez que se ha creado el gráfico TensorFlow, y todos los elementos necesario para su ejecución, tenemos que crear una sesión TensorFlow que se utiliza para ejecutar el grafo.
session = tf.Session()
# Initialize variables
def init_variables():
session.run(tf.global_variables_initializer())
#Execute the function now to initialize the variables.
init_variables()
creamos la función de iteración para el proceso de optimización, esta vez agregaremos un par de aspectos más ya que ahora consideraremos la opción de guardar:
train_batch_size = 64
La precisión de clasificación para el conjunto de validación se calculará por cada 100 iteraciones de la función de optimización. La optimización se detendrá si la precisión de la validación no se ha mejorado en 1000 iteraciones. Necesitamos algunas variables para hacer un seguimiento de esto.
# Best validation accuracy seen so far.
best_validation_accuracy = 0.0
# Iteration-number for last improvement to validation accuracy.
last_improvement = 0
# Stop optimization if no improvement found in this many iterations.
require_improvement = 1000
Creamos una función para realizar una serie de iteraciones de optimización a fin de mejorar gradualmente mediante los ajustes en las variables o parámetros de las capas de la red. En cada iteración, se selecciona un nuevo lote de datos del conjunto de entrenamiento y luego TensorFlow ejecuta el optimizador usando esas muestras de entrenamiento. El progreso se imprime cada 100 iteraciones donde la precisión de la validación también se calcula y se guarda en un archivo si se trata de una mejora, con respecto a la iteración anterior.
Creamos las función:
# Counter for total number of iterations performed so far.
total_iterations = 0
def optimize(num_iterations):
# Ensure we update the global variables rather than local copies.
global total_iterations
global best_validation_accuracy
global last_improvement
# Start-time used for printing time-usage below.
start_time = time.time()
for i in range(num_iterations):
# Increase the total number of iterations performed.
# It is easier to update it in each iteration because
# we need this number several times in the following.
total_iterations += 1
# Get a batch of training examples.
# x_batch now holds a batch of images and
# y_true_batch are the true labels for those images.
x_batch, y_true_batch = data.train.next_batch(train_batch_size)
# Put the batch into a dict with the proper names
# for placeholder variables in the TensorFlow graph.
feed_dict_train = {x: x_batch,
y_true: y_true_batch}
# Run the optimizer using this batch of training data.
# TensorFlow assigns the variables in feed_dict_train
# to the placeholder variables and then runs the optimizer.
session.run(optimizer, feed_dict=feed_dict_train)
# Print status every 100 iterations and after last iteration.
if (total_iterations % 100 == 0) or (i == (num_iterations - 1)):
# Calculate the accuracy on the training-batch.
acc_train = session.run(accuracy, feed_dict=feed_dict_train)
# Calculate the accuracy on the validation-set.
# The function returns 2 values but we only need the first.
acc_validation, _ = validation_accuracy()
# If validation accuracy is an improvement over best-known.
if acc_validation > best_validation_accuracy:
# Update the best-known validation accuracy.
best_validation_accuracy = acc_validation
# Set the iteration for the last improvement to current.
last_improvement = total_iterations
# Save all variables of the TensorFlow graph to file.
saver.save(sess=session, save_path=save_path)
# A string to be printed below, shows improvement found.
improved_str = '*'
else:
# An empty string to be printed below.
# Shows that no improvement was found.
improved_str = ''
# Status-message for printing.
msg = "Iter: {0:>6}, Train-Batch Accuracy: {1:>6.1%}, Validation Acc: {2:>6.1%} {3}"
# Print it.
print(msg.format(i + 1, acc_train, acc_validation, improved_str))
# If no improvement found in the required number of iterations.
if total_iterations - last_improvement > require_improvement:
print("No improvement found in a while, stopping optimization.")
# Break out from the for-loop.
break
# Ending time.
end_time = time.time()
# Difference between start and end-times.
time_dif = end_time - start_time
# Print the time-usage.
print("Time usage: " + str(timedelta(seconds=int(round(time_dif)))))
Ahora crearemos algunas funciones para el monitoreo del comportamiento del modelo.
def plot_example_errors(cls_pred, correct):
# This function is called from print_test_accuracy() below.
# cls_pred is an array of the predicted class-number for
# all images in the test-set.
# correct is a boolean array whether the predicted class
# is equal to the true class for each image in the test-set.
# Negate the boolean array.
incorrect = (correct == False)
# Get the images from the test-set that have been
# incorrectly classified.
images = data.test.images[incorrect]
# Get the predicted classes for those images.
cls_pred = cls_pred[incorrect]
# Get the true classes for those images.
cls_true = data.test.cls[incorrect]
# Plot the first 9 images.
plot_images(images=images[0:9],
cls_true=cls_true[0:9],
cls_pred=cls_pred[0:9])
def plot_confusion_matrix(cls_pred):
# This is called from print_test_accuracy() below.
# cls_pred is an array of the predicted class-number for
# all images in the test-set.
# Get the true classifications for the test-set.
cls_true = data.test.cls
# Get the confusion matrix using sklearn.
cm = confusion_matrix(y_true=cls_true,
y_pred=cls_pred)
# Print the confusion matrix as text.
print(cm)
# Plot the confusion matrix as an image.
plt.matshow(cm)
# Make various adjustments to the plot.
plt.colorbar()
tick_marks = np.arange(num_classes)
plt.xticks(tick_marks, range(num_classes))
plt.yticks(tick_marks, range(num_classes))
plt.xlabel('Predicted')
plt.ylabel('True')
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
funciones para calcular clasificaciones
Esta función calcula las clases de imágenes predichas y también devuelve una matriz booleana si la clasificación de cada imagen es correcta.
El cálculo se realiza en lotes porque, de lo contrario, podría usar demasiada memoria RAM. Si su computadora falla, puede intentar bajar el tamaño del lote.
# Split the data-set in batches of this size to limit RAM usage.
batch_size = 256
def predict_cls(images, labels, cls_true):
# Number of images.
num_images = len(images)
# Allocate an array for the predicted classes which
# will be calculated in batches and filled into this array.
cls_pred = np.zeros(shape=num_images, dtype=np.int)
# Now calculate the predicted classes for the batches.
# We will just iterate through all the batches.
# There might be a more clever and Pythonic way of doing this.
# The starting index for the next batch is denoted i.
i = 0
while i < num_images:
# The ending index for the next batch is denoted j.
j = min(i + batch_size, num_images)
# Create a feed-dict with the images and labels
# between index i and j.
feed_dict = {x: images[i:j, :],
y_true: labels[i:j, :]}
# Calculate the predicted class using TensorFlow.
cls_pred[i:j] = session.run(y_pred_cls, feed_dict=feed_dict)
# Set the start-index for the next batch to the
# end-index of the current batch.
i = j
# Create a boolean array whether each image is correctly classified.
correct = (cls_true == cls_pred)
return correct, cls_pred
def predict_cls_test():
return predict_cls(images = data.test.images,
labels = data.test.labels,
cls_true = data.test.cls)
def predict_cls_validation():
return predict_cls(images = data.validation.images,
labels = data.validation.labels,
cls_true = data.validation.cls)
Función para la precisión de clasificación
def cls_accuracy(correct):
# Calculate the number of correctly classified images.
# When summing a boolean array, False means 0 and True means 1.
correct_sum = correct.sum()
# Classification accuracy is the number of correctly classified
# images divided by the total number of images in the test-set.
acc = float(correct_sum) / len(correct)
return acc, correct_sum
def validation_accuracy():
# Get the array of booleans whether the classifications are correct
# for the validation-set.
# The function returns two values but we only need the first.
correct, _ = predict_cls_validation()
# Calculate the classification accuracy and return it.
return cls_accuracy(correct)
Función auxiliar para mostrar el rendimiento
Implementamos entonces la función:
def print_test_accuracy(show_example_errors=False,
show_confusion_matrix=False):
# For all the images in the test-set,
# calculate the predicted classes and whether they are correct.
correct, cls_pred = predict_cls_test()
# Classification accuracy and the number of correct classifications.
acc, num_correct = cls_accuracy(correct)
# Number of images being classified.
num_images = len(correct)
# Print the accuracy.
msg = "Accuracy on Test-Set: {0:.1%} ({1} / {2})"
print(msg.format(acc, num_correct, num_images))
# Plot some examples of mis-classifications, if desired.
if show_example_errors:
print("Example errors:")
plot_example_errors(cls_pred=cls_pred, correct=correct)
# Plot the confusion matrix, if desired.
if show_confusion_matrix:
print("Confusion Matrix:")
plot_confusion_matrix(cls_pred=cls_pred)
def plot_conv_weights(weights, input_channel=0):
# Assume weights are TensorFlow ops for 4-dim variables
# e.g. weights_conv1 or weights_conv2.
# Retrieve the values of the weight-variables from TensorFlow.
# A feed-dict is not necessary because nothing is calculated.
w = session.run(weights)
# Print mean and standard deviation.
print("Mean: {0:.5f}, Stdev: {1:.5f}".format(w.mean(), w.std()))
# Get the lowest and highest values for the weights.
# This is used to correct the colour intensity across
# the images so they can be compared with each other.
w_min = np.min(w)
w_max = np.max(w)
# Number of filters used in the conv. layer.
num_filters = w.shape[3]
# Number of grids to plot.
# Rounded-up, square-root of the number of filters.
num_grids = math.ceil(math.sqrt(num_filters))
# Create figure with a grid of sub-plots.
fig, axes = plt.subplots(num_grids, num_grids)
# Plot all the filter-weights.
for i, ax in enumerate(axes.flat):
# Only plot the valid filter-weights.
if i<num_filters:
# Get the weights for the i'th filter of the input channel.
# The format of this 4-dim tensor is determined by the
# TensorFlow API. See Tutorial #02 for more details.
img = w[:, :, input_channel, i]
# Plot image.
ax.imshow(img, vmin=w_min, vmax=w_max,
interpolation='nearest', cmap='seismic')
# Remove ticks from the plot.
ax.set_xticks([])
ax.set_yticks([])
# Ensure the plot is shown correctly with multiple plots
# in a single Notebook cell.
plt.show()
Pongamos en marcha nuestra red,
Miremos la precisión antes de cualquier optimización.
print_test_accuracy()
Accuracy on Test-Set: 8.1% (812 / 10000)
venos que la precisión del modelo con los datos de evaluación solo es de un 8.1%, dado que ningún parámetro de la red esta optimizado, solo tienen los valores que se han asignado aleatoriamente.
miramos los pesos..
plot_conv_weights(weights=weights_conv1)
y obtenemos
Mean: -0.01150, Stdev: 0.27225

Ahora realizamos 10.000 iteraciones de optimización y cancelamos aquellas optimizaciones si no se encuentra ninguna mejora en el conjunto de validación en cada 1000 iteraciones.
Se muestra un asterisco ( * ) si la precisión de la clasificación en el conjunto de validación es una mejora.
optimize(num_iterations=10000)
Iter: 100, Train-Batch Accuracy: 81.2%, Validation Acc: 84.2% ( * )
Iter: 200, Train-Batch Accuracy: 95.3%, Validation Acc: 90.5% ( * )
Iter: 300, Train-Batch Accuracy: 95.3%, Validation Acc: 92.4% ( * )
Iter: 400, Train-Batch Accuracy: 92.2%, Validation Acc: 92.5% ( * )
Iter: 500, Train-Batch Accuracy: 93.8%, Validation Acc: 94.3% ( * )
Iter: 600, Train-Batch Accuracy: 95.3%, Validation Acc: 94.9% ( * )
Iter: 700, Train-Batch Accuracy: 95.3%, Validation Acc: 95.4% ( * )
Iter: 800, Train-Batch Accuracy: 95.3%, Validation Acc: 95.8% ( * )
Iter: 900, Train-Batch Accuracy: 98.4%, Validation Acc: 96.4% ( * )
Iter: 1000, Train-Batch Accuracy: 100.0%, Validation Acc: 96.2%
Iter: 1100, Train-Batch Accuracy: 98.4%, Validation Acc: 96.7% ( * )
Iter: 1200, Train-Batch Accuracy: 92.2%, Validation Acc: 96.7%
Iter: 1300, Train-Batch Accuracy: 100.0%, Validation Acc: 97.2% ( * )
Iter: 1400, Train-Batch Accuracy: 96.9%, Validation Acc: 97.3% ( * )
Iter: 1500, Train-Batch Accuracy: 96.9%, Validation Acc: 97.2%
Iter: 1600, Train-Batch Accuracy: 95.3%, Validation Acc: 97.3% ( * )
Iter: 1700, Train-Batch Accuracy: 98.4%, Validation Acc: 97.3% ( * )
Iter: 1800, Train-Batch Accuracy: 100.0%, Validation Acc: 97.7% ( * )
Iter: 1900, Train-Batch Accuracy: 96.9%, Validation Acc: 97.6%
Iter: 2000, Train-Batch Accuracy: 98.4%, Validation Acc: 97.4%
Iter: 2100, Train-Batch Accuracy: 95.3%, Validation Acc: 97.7%
Iter: 2200, Train-Batch Accuracy: 98.4%, Validation Acc: 98.0% ( * )
Iter: 2300, Train-Batch Accuracy: 100.0%, Validation Acc: 97.9%
Iter: 2400, Train-Batch Accuracy: 100.0%, Validation Acc: 97.9%
Iter: 2500, Train-Batch Accuracy: 100.0%, Validation Acc: 97.8%
Iter: 2600, Train-Batch Accuracy: 98.4%, Validation Acc: 98.1% ( * )
Iter: 2700, Train-Batch Accuracy: 90.6%, Validation Acc: 98.2% ( * )
Iter: 2800, Train-Batch Accuracy: 100.0%, Validation Acc: 98.2%
Iter: 2900, Train-Batch Accuracy: 96.9%, Validation Acc: 98.3% ( * )
Iter: 3000, Train-Batch Accuracy: 100.0%, Validation Acc: 98.1%
Iter: 3100, Train-Batch Accuracy: 98.4%, Validation Acc: 98.2%
Iter: 3200, Train-Batch Accuracy: 98.4%, Validation Acc: 98.3%
Iter: 3300, Train-Batch Accuracy: 100.0%, Validation Acc: 98.2%
Iter: 3400, Train-Batch Accuracy: 100.0%, Validation Acc: 98.4% ( * )
Iter: 3500, Train-Batch Accuracy: 100.0%, Validation Acc: 98.4%
Iter: 3600, Train-Batch Accuracy: 100.0%, Validation Acc: 98.4%
Iter: 3700, Train-Batch Accuracy: 98.4%, Validation Acc: 98.3%
Iter: 3800, Train-Batch Accuracy: 96.9%, Validation Acc: 98.4%
Iter: 3900, Train-Batch Accuracy: 98.4%, Validation Acc: 98.6% ( * )
Iter: 4000, Train-Batch Accuracy: 98.4%, Validation Acc: 98.2%
Iter: 4100, Train-Batch Accuracy: 98.4%, Validation Acc: 98.4%
Iter: 4200, Train-Batch Accuracy: 95.3%, Validation Acc: 98.6%
Iter: 4300, Train-Batch Accuracy: 100.0%, Validation Acc: 98.3%
Iter: 4400, Train-Batch Accuracy: 98.4%, Validation Acc: 98.6% ( * )
Iter: 4500, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7% ( * )
Iter: 4600, Train-Batch Accuracy: 100.0%, Validation Acc: 98.7% ( * )
Iter: 4700, Train-Batch Accuracy: 100.0%, Validation Acc: 98.4%
Iter: 4800, Train-Batch Accuracy: 96.9%, Validation Acc: 98.6%
Iter: 4900, Train-Batch Accuracy: 96.9%, Validation Acc: 98.7%
Iter: 5000, Train-Batch Accuracy: 98.4%, Validation Acc: 98.5%
Iter: 5100, Train-Batch Accuracy: 95.3%, Validation Acc: 98.7%
Iter: 5200, Train-Batch Accuracy: 100.0%, Validation Acc: 98.8% ( * )
Iter: 5300, Train-Batch Accuracy: 100.0%, Validation Acc: 98.5%
Iter: 5400, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 5500, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 5600, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 5700, Train-Batch Accuracy: 100.0%, Validation Acc: 98.9% ( * )
Iter: 5800, Train-Batch Accuracy: 100.0%, Validation Acc: 98.7%
Iter: 5900, Train-Batch Accuracy: 100.0%, Validation Acc: 98.5%
Iter: 6000, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 6100, Train-Batch Accuracy: 100.0%, Validation Acc: 98.8%
Iter: 6200, Train-Batch Accuracy: 98.4%, Validation Acc: 98.8%
Iter: 6300, Train-Batch Accuracy: 100.0%, Validation Acc: 98.7%
Iter: 6400, Train-Batch Accuracy: 100.0%, Validation Acc: 98.7%
Iter: 6500, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 6600, Train-Batch Accuracy: 100.0%, Validation Acc: 98.9% ( * )
Iter: 6700, Train-Batch Accuracy: 98.4%, Validation Acc: 98.8%
Iter: 6800, Train-Batch Accuracy: 96.9%, Validation Acc: 98.9%
Iter: 6900, Train-Batch Accuracy: 100.0%, Validation Acc: 98.8%
Iter: 7000, Train-Batch Accuracy: 100.0%, Validation Acc: 98.8%
Iter: 7100, Train-Batch Accuracy: 96.9%, Validation Acc: 98.2%
Iter: 7200, Train-Batch Accuracy: 100.0%, Validation Acc: 98.7%
Iter: 7300, Train-Batch Accuracy: 100.0%, Validation Acc: 98.8%
Iter: 7400, Train-Batch Accuracy: 100.0%, Validation Acc: 98.9%
Iter: 7500, Train-Batch Accuracy: 100.0%, Validation Acc: 98.6%
Iter: 7600, Train-Batch Accuracy: 98.4%, Validation Acc: 98.9% ( * )
Iter: 7700, Train-Batch Accuracy: 98.4%, Validation Acc: 99.0% ( * )
Iter: 7800, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 7900, Train-Batch Accuracy: 96.9%, Validation Acc: 98.9%
Iter: 8000, Train-Batch Accuracy: 98.4%, Validation Acc: 98.7%
Iter: 8100, Train-Batch Accuracy: 100.0%, Validation Acc: 98.9%
Iter: 8200, Train-Batch Accuracy: 100.0%, Validation Acc: 98.7%
Iter: 8300, Train-Batch Accuracy: 98.4%, Validation Acc: 98.8%
Iter: 8400, Train-Batch Accuracy: 98.4%, Validation Acc: 98.8%
Iter: 8500, Train-Batch Accuracy: 100.0%, Validation Acc: 98.9%
Iter: 8600, Train-Batch Accuracy: 100.0%, Validation Acc: 98.8%
Iter: 8700, Train-Batch Accuracy: 96.9%, Validation Acc: 98.9%
No improvement found in a while, stopping optimization.
Time usage: 0:14:17
miramos la precisión del modelo después de la optimización:
print_test_accuracy(show_example_errors=False,
show_confusion_matrix=True)
Accuracy on Test-Set: 98.8% (9882 / 10000)
Confusion Matrix:
[[ 976 0 0 0 0 1 1 0 1 1]
[ 0 1132 1 0 0 0 1 1 0 0]
[ 4 3 1008 2 1 0 0 4 9 1]
[ 2 0 0 999 0 5 0 0 3 1]
[ 0 0 0 0 975 0 0 0 3 4]
[ 2 0 0 4 0 883 1 0 0 2]
[ 10 2 0 1 1 4 938 0 2 0]
[ 1 0 4 3 0 1 0 1015 1 3]
[ 4 0 0 0 0 2 0 2 962 4]
[ 1 3 0 1 6 3 0 1 0 994]]
Vemos como aumenta notablemente la precisión del modelo.
Miramos los pesos después de la optimización
plot_conv_weights(weights=weights_conv1)
Mean: 0.01089, Stdev: 0.29140
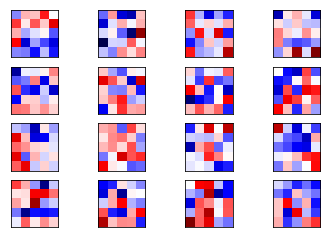
Ahora reinicializar todas las variables de la red neuronal con valores aleatorios, y esta vez nos optmizaremos la red sino que recuperaremos los valores de losparámetros del grafo ya optimizados.
init_variables()
print_test_accuracy()
Accuracy on Test-Set: 6.7% (673 / 10000)
Mean: 0.02489, Stdev: 0.27997
Vemos que la precisión vuelve a ser baja,
Vamos a cargar todas las variables que se guardaron en el archivo durante la optimización.
saver.restore(sess=session, save_path=save_path)
INFO:tensorflow:Restoring parameters from checkpoints/best_validation
Miramos la precisión nuevamente
print_test_accuracy(show_example_errors=False,
show_confusion_matrix=True)
Accuracy on Test-Set: 98.8% (9884 / 10000)
Confusion Matrix:
[[ 974 0 0 0 0 0 3 0 2 1]
[ 0 1132 1 0 0 0 1 1 0 0]
[ 2 3 1015 2 1 0 0 3 6 0]
[ 1 0 1 1002 0 2 0 2 1 1]
[ 0 0 0 0 975 0 2 0 3 2]
[ 2 0 0 6 0 881 1 0 0 2]
[ 4 1 0 1 1 1 950 0 0 0]
[ 1 1 5 2 0 1 0 1014 1 3]
[ 4 0 1 3 1 3 1 2 956 3]
[ 1 3 0 1 10 2 0 6 1 985]]
Como podemo comprobar a partir del la medida de redimiento (accuracy) y con la matriz de confusión, hemos recuperado la precisión del modelo,con la particularidad de que esta vez, no hemos tenido que optimizar ningun parámetyro, sino que hemos usado los valores optimizados que han sido guardados .
cerramos la sesión para liberar recursos.
# This has been commented out in case you want to modify and experiment
# with the Notebook without having to restart it.
session.close()
Este tutorial mostró cómo guardar y recuperar las variables de una red neuronal en TensorFlow. Esto se puede usar de diferentes maneras. Por ejemplo, si desea utilizar una red neuronal para reconocer imágenes, solo debe entrenar la red una vez y luego puede implementar la red terminada en otras computadoras.
Otro uso de los puntos de control es que si tiene una red neuronal y un conjunto de datos muy grandes, puede guardar los puntos de control a intervalos regulares en caso de que la computadora falle, por lo que puede continuar la optimización en un punto de control reciente en lugar de tener que reiniciar optimización desde el principio.
Este tutorial también mostró cómo usar el conjunto de validación para la llamada téctica de Early Stopping., donde la optimización se anuló si no mejoraba regularmente el error de validación. Esto es útil si la red neuronal comienza a sobreajustarse y aprender el ruido del conjunto de entrenamiento; aunque no fue realmente un problema con la red convolucional y el conjunto de datos MNIST utilizado en este tutorial.
Si estás interesado en nuestro servicios de análisis de datos y el uso de Machine Learning para mejorar el rendimiento en tu empresa puedes escribirnos a info@apsl.net para cualquier información y/o asesorías.








